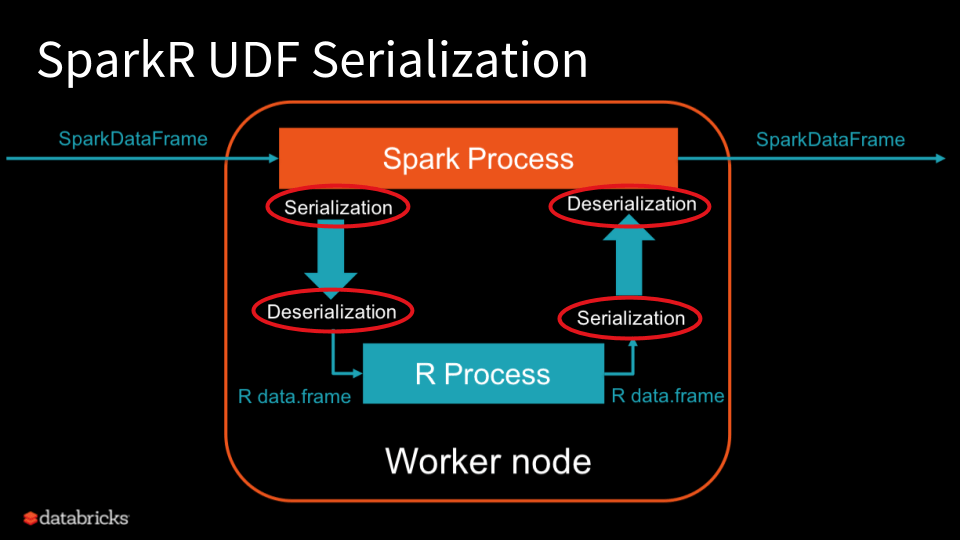
This is a joint guest community blog by Li Jin at Two Sigma and Kevin Rasmussen at Databricks; they share how to use Flint with Apache Spark.
Introduction
The volume of data that data scientists face these days increases relentlessly, and we now find that a traditional, single-machine solution is no longer adequate to the demands of these datasets. Over the past few years, Apache Spark has become the standard for dealing with big-data workloads, and we think it promises data scientists huge potential for analysis of large time series. We have developed Flint at Two Sigma to enhance Spark’s functionality for time series analysis. Flint is an open source library and available via Maven and PyPI.
Time Series Analysis
Time series analysis has two components: time series manipulation and time series modeling.
Time series manipulation is the process of manipulating and transforming data into features for training a model. Time series manipulation is used for tasks like data cleaning and feature engineering. Typical functions in time series manipulation include:
- Joining: joining two time-series datasets, usually by the time
- Windowing: feature transformation based on a time window
- Resampling: changing the frequency of the data
- Filling in missing values or removing NA rows.
Time series modeling is the process of identifying patterns in time-series data and training models for prediction. It is a complex topic; it includes specific techniques such as ARIMA and autocorrelation, as well as all manner of general machine learning techniques (e.g., linear regression) applied to time series data.
Flint focuses on time series manipulation. In this blog post, we demonstrate Flint functionalities in time series manipulation and how it works with other libraries, e.g., Spark ML, for a simple time series modeling task.
Flint Overview
Flint takes inspiration from an internal library at Two Sigma that has proven very powerful in dealing with time-series data.
Flint’s main API is its Python API. The entry point — TimeSeriesDataFrame — is an extension to PySpark DataFrame and exposes additional time series functionalities.
Here is a simple example showing how to read data into Flint and use both PySpark DataFrame and Flint functionalities:
from ts.flint import FlintContext
flintContext = FlintContext(sqlContext)
df = spark.createDataFrame(
[('2018-08-20', 1.0), ('2018-08-21', 2.0), ('2018-08-24', 3.0)],
['time', 'v']
).withColumn('time', from_utc_timestamp(col('time'), 'UTC'))
# Convert to Flint DataFrame
flint_df = flintContext.read.dataframe(df)
# Use Spark DataFrame functionality
flint_df = flint_df.withColumn('v', flint_df['v'] + 1)
# Use Flint functionality
flint_df = flint_df.summarizeCycles(summarizers.count())
Flint Functionalities
In this section, we introduce a few core Flint functionalities to deal with time series data.
Asof Join
Asof Join means joining on time, with inexact matching criteria. It takes a tolerance parameter, e.g, ‘1day’ and joins each left-hand row with the closest right-hand row within that tolerance. Flint has two asof join functions: LeftJoin and FutureLeftJoin. The only difference is the temporal direction of the join: whether to join rows in the past or the future.
For example…
left = ...
# time, v1
# 20180101, 100
# 20180102, 50
# 20180104, -50
# 20180105, 100
right = ...
# time, v2
# 20171231, 100.0
# 20180104, 105.0
# 20180105, 102.0
joined = left.leftJoin(right, tolerance='1day')
# time, v1, v2
# 20180101, 100, 100.0
# 20180102, 50, null
# 20180104, -50, 105.0
# 20180105, 100, 102.0
Asof Join is useful for dealing with data with different frequency, misaligned timestamps, etc. Further illustrations of this function appear below, in the Case Study section.
AddColumnsForCycle
Cycle in Flint is defined as “data with the same timestamp”. It is common for people to want to transform data with the same timestamp, for instance, to rank features that have the same timestamp. AddColumnsForCycle is a convenient function for this type of computation.
AddColumnsForCycle takes a user defined function that maps a Pandas series to another Pandas series of the same length.
Some examples include:
Rank values for each cycle:
from ts.flint import udf
@udf('double')
def rank(v):
# v is a pandas.Series
return v.rank(pct=True)
df = …
# time, v
# 20180101, 1.0
# 20180101, 2.0
# 20180101, 3.0
df = df.addColumnsForCycle({'rank': rank(df['v'])})
# time, v, rank
# 20180101, 1.0, 0.333
# 20180101, 2.0, 0.667
# 20180101, 3.0, 1.0
Box-Cox transformation is a useful data transformation technique to make the data more like a normal distribution. The following example performs Box-Cox transformation for each cycle:
import pandas as pd
from scipy import stats
@udf('double')
def boxcox(v):
return pd.Series(stats.boxcox(v)[0])
df = …
# time, v
# 20180101, 1.0
# 20180101, 2.0
# 20180101, 3.0
df = df.addColumnsForCycle({'v_boxcox': boxcox(df['v'])})
# time, v, v_boxcox
# 20180101, 1.0, 0.0
# 20180101, 2.0, 0.852
# 20180101, 3.0, 1.534
Summarizer
Flint summarizers are similar to Spark SQL aggregation functions. Summarizers compute a single value from a list of values. See a full description of Flint summarizers here: http://ts-flint.readthedocs.io/en/latest/reference.html#module-ts.flint.summarizers.
Flint’s summarizer functions are:
- summarize: aggregate data across the entire data frame
- summarizeCycles: aggregate data with the same timestamp
- summarizeIntervals: aggregate data that belongs to the same time range
- summarizeWindows: aggregate data that belongs to the same window
- addSummaryColumns: compute cumulative aggregation, such as cumulative sum
An example includes computing maximum draw-down:
import pyspark.sql.functions as F
# Returns of a particular stock.
# 1.01 means the stock goes up 1%; 0.95 means the stock goes down 5%
df = ...
# time, return
# 20180101, 1.01
# 20180102, 0.95
# 20180103, 1.05
# ...
# The first addSummaryColumns adds a column 'return_product' which is the cumulative return of each day
# The second addSummaryColumns adds a column 'return_product_max' which is the max cumulative return up until each day
cum_returns = df.addSummaryColumns(summarizers.product('return')) \
.addSummaryColumns(summarizers.max('return_product')) \
.toDF('time', 'return', 'cum_return', 'max_cum_return')
drawdowns = cum_returns.withColumn(
'drawdown',
1 - cum_returns['cum_return'] / cum_returns['max_cum_return'])
max_drawdown = drawdowns.agg(F.max('drawdown'))
Window
Flint’s summarizeWindows function is similar to rolling window functions in Spark SQL in that it can compute things like rolling averages. The main difference is that summarizeWindows doesn’t require a partition key and can, therefore, handle a single large time series.
Some examples include:
Compute rolling exponential moving average:
from ts.flint import windows
w = windows.past_absolute_time('7days')
df = ...
# time, v
# 20180101, 1.0
# 20180102, 2.0
# 20180103, 3.0
df = df.summarizeWindows(w, summarizers.ewma('v', alpha=0.5))
# time, v, v_ewma
# 20180101, 1.0, 1.0
# 20180102, 2.0, 2.5
# 20180103, 3.0, 4.25
Case Study
Now we consider an example where Flint functionalities perform a simple time-series analysis.
Data Preparation
We have downloaded daily price data for the S&P 500 into a CSV file. First we read the file into a Flint data frame and add a “return” column:
from ts.flint import FlintContext
flintContext = FlintContext(sqlContext)
sp500 = flintContext.read.dataframe(spark.read.option('header', True).option('inferSchema', True).csv('sp500.csv'))
sp500_return = sp500.withColumn('return', 10000 * (sp500['Close'] - sp500['Open']) / sp500['Open']).select('time', 'return')
Here, we want to test a very simple idea: can a previous day’s returns be used to predict the next day’s returns? To test the idea, we first need to self-join the return table, so as to create a “preview_day_return” column:
sp500_previous_day_return = sp500_return.shiftTime(windows.future_absolute_time('1day')).toDF('time', 'previous_day_return')
sp500_joined_return = sp500_return.leftJoin(sp500_return_previous_day)
But there is a problem with the joined result: previous_day_return for Mondays are null! That is because we don’t have any return data on weekends, so Monday cannot simply join the return data from Sunday. To deal with this problem, we set the tolerance parameter of leftJoin to ‘3days’, a duration large enough to cover two-day weekends, so Monday can join with last Friday’s returns:
sp500_joined_return = sp500_return.leftJoin(sp500_previous_day_return, tolerance='3days').dropna()
Feature Engineering
Next we use Flint for some feature transformation. In time-series analysis, it’s quite common to transform a feature based on its past values. Flint’s summarizeWindows function can be used for this type of transformation. Below we offer two examples of time-based feature transformation using summarizeWindows: one with built-in summarizer and one with user-defined functions (UDF).
Built-in summarizer:
from ts.flint import summarizers
sp500_decayed_return = sp500_joined_return.summarizeWindows(
window = windows.past_absolute_time('7day'),
summarizer = summarizers.ewma('previous_day_return', alpha=0.5)
)
UDF:
from ts.flint import udf
@udf('double', arg_type='numpy')
def decayed(columns):
v = columns[0]
decay = np.power(0.5, np.arange(len(v)))[::-1]
return (v * decay).sum()
sp500_decayed_return = sp500_joined_return.summarizeWindows(
window = windows.past_absolute_time('7day'),
summarizer = {'previous_day_decayed_return':
decayed(sp500_joined_return[['previous_day_return']])})
Model Training
Now that we have prepared the data, we can train a model on it. Here we use Spark ML to fit a linear regression model:
from pyspark.ml.regression import LinearRegression
from pyspark.ml.feature import VectorAssembler
assembler = VectorAssembler(
inputCols=["previous_day_return", "previous_day_decayed_return"],
outputCol="features")
output = assembler.transform(sp500_decayed_return).select('return', 'features').toDF('label', 'features')
lr = LinearRegression(maxIter=10, regParam=0.3, elasticNetParam=0.8)
model = lr.fit(output)
Now that we’ve trained the model, a reasonable next step would be to inspect the results by introspecting the model object to see whether our idea actually works. That takes us outside of our scope in this blog post, so (as the saying goes) we leave model evaluation as an exercise for the reader.
You can try this notebook at Flint Demo (Databricks Notebook); refer to databricks-flint for more information.
Summary and Future Roadmap
Flint is a useful library for time-series analysis, complementing other functionality available in Spark SQL. In internal research at Two Sigma, there have been many success stories in using Flint to scale up time-series analysis. We are publishing Flint now, in the hope that it addresses common needs for time-series analysis with Spark. We look forward to working with the Apache Spark community in making Flint an asset not just for Two Sigma, but for the entire community.
In the near future, we plan to start conversations with core Spark maintainers, to discuss a path to make that happen. We also plan to integrate Flint with Catalyst and Tungsten to achieve better performance.
--
Try Databricks for free. Get started today.
The post Introducing Flint: A time-series library for Apache Spark appeared first on Databricks.