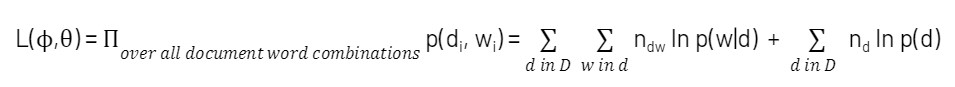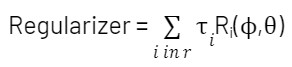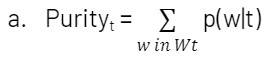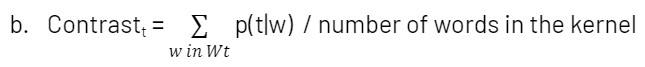Data sharing has become an essential component to drive business value as companies of all sizes look to securely exchange data with their customers, suppliers and partners. According to a recent Gartner survey, organizations that promote data sharing will outperform their peers on most business value metrics.
There are various challenges with the existing data sharing solutions that limit the data sharing within or across organizations and fail to realize the true value of data. Over the last 30 years, data sharing solutions have come in two forms: homegrown solutions or third-party commercial solutions. With homegrown solutions, data sharing has been built on legacy technologies such as SFTP and REST APIs, which have become difficult to manage, maintain or scale with new data requirements. Alternatively, commercial data sharing solutions only allow you to share data with others leveraging the same platform, which limits the data sharing and can be costly.
These challenges have led us, at Databricks, to rethink the future of data sharing as open. During the Data + AI Summit 2021, we announced Delta Sharing, the world’s first open protocol for secure and scalable real-time data sharing. Our vision behind Delta Sharing is to build a data-sharing solution that simplifies secure live data sharing across organizations, independent of the platform on which the data resides or is consumed. With Delta Sharing, organizations can easily share existing large-scale datasets based on the Apache Parquet and Delta Lake formats without moving data and empower data teams with the flexibility to query, visualize and enrich shared data with their tools of choice.

Delta Sharing ecosystem
Since the private preview launch, we have seen tremendous engagement from customers across industries to collaborate and develop a data-sharing solution fit for purpose and open to all. Customers have already shared petabytes of data using Delta Sharing. The Delta Sharing partner ecosystem has also grown since the announcement with both commercial and open-source clients having built-in Delta Sharing connectors such as PowerBI, Pandas, and Apache Spark™ with many others to be released soon.
Through our customer conversations, we have identified three common use cases: data commercialization, data sharing with external partners and customers, and line of business data sharing. In this blog post, we explore each one of the top use cases and share some of the insights we are hearing from our customers.
Use case 1: Data commercialization
Customer example: A financial data provider was interested in reducing operational inefficiencies with their legacy data delivery channels and making it easier for the end customers to seamlessly access large new datasets.
Challenges
The data provider recently launched new textual datasets that were large in size, with terabytes of data being produced regularly. Providing quick and easy access to these large datasets has been a persistent challenge for the data provider as the datasets were difficult to ingest in bulk for the data recipients. With the current solution, the provider had to replicate data to external SFTP servers, which had many potential points of failure and increased latency.
On the recipient side, ingesting and managing this data was not easy due to its size and scale. Data recipients had to set up infrastructure for ingestion, which further required approvals from IT and database administrators, resulting in delays that could take weeks if not longer to complete before the end consumer could start using the data.
How Delta Sharing helps
With Delta Sharing, the data provider can now share large datasets in a seamless manner and overcome the scalability issues with the SFTP servers. These large terabyte sized textual datasets which had to be extracted in batches to SFTP can now be accessed in real time through Delta Sharing. The provider now can simply grant and manage access to the data recipients instead of replicating the data, thereby reducing complexity and latency. With the improved scalability, the data provider is seeing a significant increase in customer adoption as the data consumers have access to live data instead of having to pull the datasets on a regular basis.
Use case 2: Data sharing with external partners/customers
Customer example: A large retailer needed to easily share product data (e.g., cereal SKU sales) with partners without being on the same data sharing or cloud computing platform as them. The retailer wanted to create partitioned datasets based on SKUs for partners to easily access the relevant data in real time.
Challenges
The retailer was utilizing homegrown SFTP and APIs to share data with partners, which had become unmanageable. This solution required a considerable amount of development resources to maintain and operate. The retailer looked at other data sharing solutions, but these solutions required their partners to be on the same platform, which is not feasible for all parties due to cost considerations and operational overhead of replicating data across different regions.
How Delta Sharing helps
Delta Sharing was an exciting proposition for the retailer to manage and share data efficiently across cloud platforms without the need to replicate the data across regions. The retailer found it easy to manage, create and audit data shares for their 100+ partners through Delta Sharing. For each partner, the retailer can easily create partitions and share the data securely without the need to be on the same data platform. In addition to making the management of the shares easy, Delta Sharing also minimizes the cost, as the data provider only incurs data egress cost from the underlying cloud provider and does not have to pay for any compute charges for data sharing.
Use case 3: Internal data sharing with line of business
Customer example: A manufacturer wants data scientists across its 15+ divisions and subsidiaries to have access to permissioned data to build predictive models. The manufacturer wants to do this with strong governance, controls, and auditing capabilities because of data sensitivity.
Challenges
The manufacturer has many data lake deployments, making it difficult for teams across the organization to access the data securely and efficiently. Managing all this data across the organization is done in a bespoke manner with no strong controls over entitlements and governance. Additionally, many of these datasets are petabytes in size causing concern in the ability to scalably share this data. Management was hesitant about sharing data without the proper data access controls and governance. As a result, the manufacturer was missing unique opportunities to unlock value and allow more unique insights for the data science teams.
How Delta Sharing helps
With Delta Sharing, the manufacturer now has the ability to govern and share data across distinct internal entities without having to move data. Delta Sharing lets the manufacturer grant, track, and audit access to shared data from a single point of enforcement. Without having to move these large datasets, the manufacturer doesn’t have to worry about managing different services to replicate the data. Delta Sharing enabled the manufacturer to securely share data much quicker than they expected, allowing for immediate benefits as the end-users could begin working with unique datasets that were previously siloed. The manufacturer is also excited to utilize the built-in Delta Sharing connector with PowerBI, which is their tool of choice for data visualization.
Getting started with Delta Sharing
Delta Sharing makes it simple to share data with other organizations regardless of which data platforms they use. We are thrilled to share the first solution that provides an open and secure solution without proprietary lock-in that helps data teams easily share data, manage privacy, security and compliance across organizations.
To try Delta Sharing on Databricks, reach out to your Databricks account executive or sign up to get an early access. For many of our customers, governance is top of mind when sharing data. Delta Sharing is natively integrated with Unity Catalog, which enables customers to add fine-grained governance and security controls, making it easy and safe to share data internally or externally. Once you have enabled Unity Catalog in your databricks account, try out the quick start notebooks below to get started with Delta Sharing on Databricks:
- Creating a share and granting access to a data recipient
- Connecting to a share and accessing the data
To try the open source Delta Sharing release, follow the instructions at delta.io/sharing.
Interested in participating in the Delta Sharing open source project?
We’d love to get your feedback on the Delta Sharing project and ideas or contributions for new features. Get involved with the Delta Sharing community by following the instructions here.
--
Try Databricks for free. Get started today.
The post Top Three Data Sharing Use Cases With Delta Sharing appeared first on Databricks.