There is a breach! You are an infosec incident responder and you get called in to investigate. You show up and start asking people for network traffic log and telemetry data. People start sharing terabytes of data with you, pointing you to various locations in cloud storage. You compile a list of hundreds of IP addresses and domain names as indicators of compromise (IOCs). To start, you want to check if any of those IOCs show up in the log and telemetry data given to you. You take a quick look and realize that there is log data from all the different systems, security appliances, and cloud providers that the organization uses – lots of different schemas and formats. How would you analyze this data? You cannot exactly download the data onto a laptop and perform grep. You cannot exactly put this into a Security Information and Event Management (SIEM) system either – it will be cumbersome to set up, too expensive and likely too slow. How would you query for IOCs over the different schemas? You imagine spending days figuring out the different schemas.
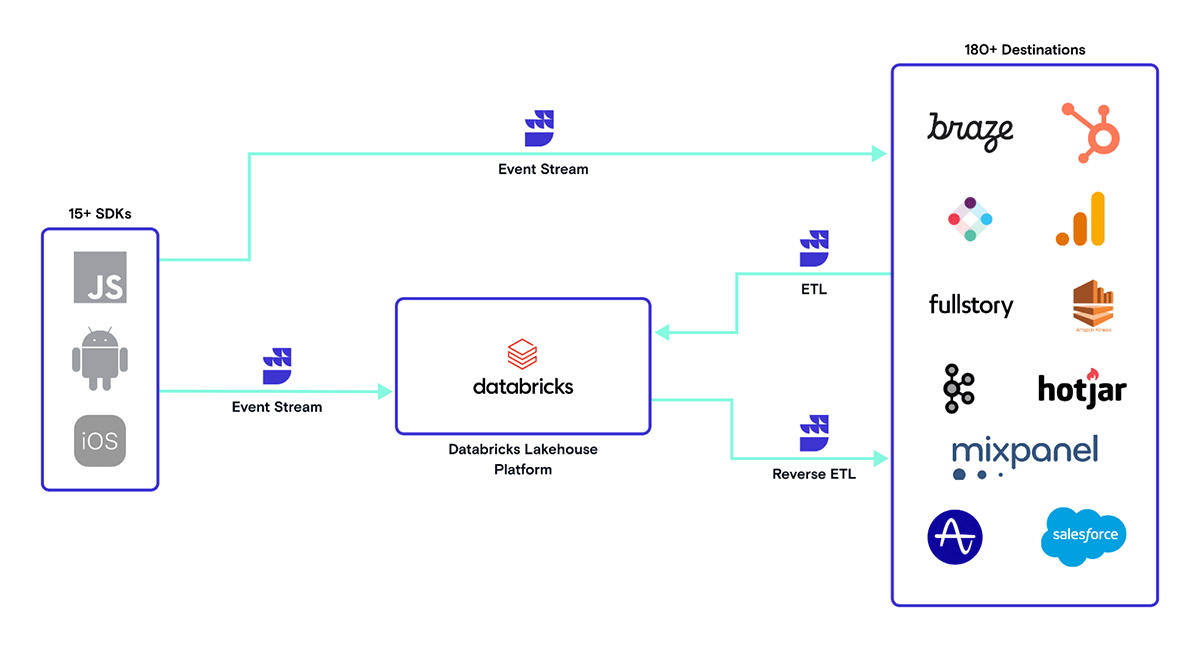
Now imagine if you had the Databricks Lakehouse platform. All the log and telemetry data exported from the organization’s systems, security sensors and cloud providers can be ingested directly into Databricks Lakehouse delta tables (also stored in inexpensive cloud storage). Delta tables also facilitate high performance analytics and AI/ML. Since Databricks can operate in multiple clouds, there is no need to consolidate data into a single cloud when the data resides in multiple clouds. You can filter the data in Databricks over multiple clouds and get the results as parquet files via the Delta Sharing protocol. Hence you only pay egress costs for query results not data ingestion! Imagine the kinds of queries, analytics and AI/ML models you could run on such a cybersecurity platform as you deep dive into an incident response (IR) investigation. Imagine how easy it would be to search for those IOCs.
In this blog, we will
- explain the IOC matching problem in cybersecurity operations,
- show you how to perform IOC matching on logs and telemetry data stored in the Databricks Lakehouse platform without knowing the table names or field names,
- show you how to extend ad hoc queries to do continuous or incremental monitoring, and
- show you how to create summary structures to increase time coverage and speed up historical IOC searches.
At the end of this blog, you will be able to take the associated notebook and sample data and try this in your own Databricks workspace.
Why is IOC matching important?
Detection
Matching of atomic IOCs is a fundamental building block of detection rules or models used by detection systems such as endpoint detection and response (EDR) systems and Intrusion detection (IDS) systems. An atomic IOC can be an IP address, a fully qualified domain name (FQDN), a file hash (MD5, SHA1, SHA256 etc.), a TLS fingerprint, a registry key or a filename associated with a potential intrusion or malicious activity. Detection systems typically use (atomic) IOC matching in conjunction with other predicates to detect a cyber threat and generate a security incident alert with relatively high confidence.
For example, consider the IOC for the FQDN of a malicious command and control (C2) server. The detection rule needs to find a domain name system (DNS) request that matches that FQDN in the logs, verify that the request was successful, verify that the host that sent that request attempted to connect to the IP address associated with the FQDN before generating an alert. Alerts from a detection system are typically aggregated, prioritized, and triaged by the security operations center (SOC) of an organization. Most alerts are false positives, but when a true positive alert is discovered, an incident response workflow is triggered.
Incident Response (IR)
When a breach, such as the SolarWinds hack, is suspected, one of the first tasks incident responders will do is to construct a list of relevant IOCs and scan all logs and telemetry data for those IOCs.The result of the scan, or IOC matching, is a list of IOC hits (sometimes also called leads or low fidelity alerts). These IOC hits are then scrutinized by incident responders and a deeper forensic investigation is conducted on the impacted systems. The intent of the forensic investigation is to establish the timeline and the scope of the breach.
Threat Hunting
Threat hunting is a proactive search for security threats that have evaded the existing detection systems. Threat hunting typically starts with an IOC search across all available logs and telemetry data. The list of IOCs used for hunting is typically curated from organization-specific threats found in the past, public news/blogs, and threat intelligence sources. We can further break down threat intelligence sources into paid subscriptions like (VirusTotal etc.), open source (Facebook ThreatExchange), and law enforcement (FBI, DHS, CyberCommand).
In both IR and threat hunting use cases, the incident responder or threat hunter (henceforth “analyst”) will perform IOC matching to obtain a list of IOC hits. These hits are grouped by devices (hosts, servers, laptops, etc.) on which the event associated with the IOC occurred. For each of these groups, the analyst will pull and query additional data just prior to the event timestamp. Those data include process executions, file downloads, user accounts and are sometimes enriched with threat intelligence (eg. check file hashes against VirusTotal). If the triggering event is deemed malicious, remediation actions like isolating or quarantining the device might be taken. Note that a limitation of IOCs from threat intelligence subscriptions is that they are limited to “public” indicators (eg. public IP addresses) – some malicious actors hijack the victims infrastructure and hence operate out of a private IP address that is harder to detect. In any case, the investigation process is driven by the IOC matching operation and hence its importance in cybersecurity operations.
Why is IOC matching difficult?
Consider the IOC matching for IR use case. In the best case all the data sits in a security information and event management (SIEM) system and thus can be easily queried; however, a SIEM typically has a relatively short retention period (typically less than 90 days in hot storage) due to costs and some threats may operate in the organization’s environment for as long as a year. The Solarwinds, or Sunburst breach of 2020 is a good example: the earliest activity dates back to February 2020 even though the breach was only discovered in November 2020. Moreover, even if you can afford to keep a year’s worth of data in a SIEM, most legacy SIEMs are not able to query over that much data at interactive speeds and many analysts end up “chunking” up the query into multiple queries that cover a short period (e.g., a week) at a time. In other cases, the data might sit across multiple siloed data stores with longer retention, but significant effort will be needed to perform IOC matching over the disparate data stores.
Even when an external cybersecurity vendor is engaged for the IR, the vendor IR team will often want to pull the customer data back into a central data store with the capabilities of performing IOC matching and analytics. One difficulty will be the variability in the data schemas of the data being pulled back and some effort will be needed to deal with the schema variability either using schema-on-write or schema-on-read techniques. Another difficulty will be the coverage of the search in terms of time or data retention. Given the urgency of an IR, only a recent time window of data is pulled back and scrutinized, because it is often difficult or infeasible to acquire the volume of data covering a long retention period. Note that data acquisition in an IR can be very complex: the customer may not have a secure, long-retention, and tamper-proof logging facility; the logs might have rolled on the source systems due to limited storage; the threat actors might tamper with the logs to cover their tracks.
The threat hunting use case faces similar data engineering challenges, but has an additional difficulty in that the list of IOCs to be matched can be in the hundreds or thousands. While performing single IOC matching might still be acceptable for the IR use case where the list of IOCs is in the tens, that approach will not be feasible for threat hunting. IOC matching for threat hunting needs to be treated like a database join operation and leverage the various high performance join algorithms developed by the database community.
IOC Matching using the Databricks Lakehouse Platform
Now back to the incident response (IR) scenario we started the blog with – how would you do IOC matching over all your log and telemetry data?
If you have a SIEM, you can run a query matching a single or a list of IOCs, but we have already mentioned the limitations. Maybe you build your own solution by sending and storing all your logs and telemetry in cheap cloud storage like AWS S3 (or Azure Data Lake Storage (ADLS) or Google cloud storage). You will still need a query engine like Presto/Trino, AWS Athena, AWS Redshift, Azure Data Explorer, or Google Big Query to query the data. Then you will also need a user interface (UI) that would support the collaboration needed for most IR and threat hunting use cases. Gluing all those pieces together into a functional solution still takes significant engineering effort.
The good news is that the Databricks Lakehouse platform is a single unified data platform that:
- lets you ingest all the logs and telemetry from their raw form in cloud storage into delta tables (also in cloud storage) using the Delta Lake framework (the Delta Lake frame uses an open format and supports fast, reliable and scalable query processing);
- supports both analytics and AI/ML workloads on the same delta tables – no copying or ETL needed;
- supports collaborative workflows via the notebook UI as well as via a set of rich APIs and integrations with other tools and systems;
- Supports both streaming and batch processing in the same runtime environment.
Databricks for the IR Scenario
Let us dive into the IR scenario assuming all the data has been ingested into the Databricks Lakehouse platform. You want to check if any of those IOCs you compiled has occurred in any of the logs and telemetry data for the past 12 months. Now you are faced with the following questions:
- Which databases, tables and columns contain relevant data that should be checked for IOCs?
- How do we extract the indicators (IP addresses, FQDNs) from the relevant columns?
- How do we express the IOC matching query as an efficient JOIN query?
The first question is essentially a schema discovery task. You are free to use a third party schema discovery tool, but it is also straightforward to query the Databricks metastore for the metadata associated with the databases, tables and columns. The following code snippet does that and puts the results into a temporary view for further filtering.
db_list = [x[0] for x in spark.sql("SHOW DATABASES").collect()]
excluded_tables = ["test01.ioc", "test01.iochits"]
# full list = schema, table, column, type
full_list = []
for i in db_list:
try:
tb_df = spark.sql(f"SHOW TABLES IN {i}")
except Exception as x:
print(f"Unable to show tables in {i} ... skipping")
continue
for (db, table_name, is_temp) in tb_df.collect():
full_table_name = db + "." + table_name
if is_temp or full_table_name in excluded_tables:
continue
try:
cols_df = spark.sql(f"DESCRIBE {full_table_name}")
except Exception as x:
# most likely the exception is a permission denied, because the table is not visible to this user account
print(f"Unable to describe {full_table_name} ... skipping")
continue
for (col_name, col_type, comment) in cols_df.collect():
if not col_type or col_name[:5]=="Part ":
continue
full_list.append([db, table_name, col_name, col_type])
spark.createDataFrame(full_list, schema = ['database', 'tableName', 'columnName', 'colType']).createOrReplaceTempView("allColumns")
display(spark.sql("SELECT * FROM allColumns"))
You then write a SQL query on the temporary view to find the relevant columns using simple heuristics in the WHERE-clause.
metadata_sql_str = """
SELECT database, tableName,
collect_set(columnName) FILTER
(WHERE columnName ilike '%orig%'
OR columnName ilike '%resp%'
OR columnName ilike '%dest%'
OR columnName ilike '%dst%'
OR columnName ilike '%src%'
OR columnName ilike '%ipaddr%'
OR columnName IN ( 'query', 'host', 'referrer' )) AS ipv4_col_list,
collect_set(columnName) FILTER
(WHERE columnName IN ('query', 'referrer')) AS fqdn_col_list
FROM allColumns
WHERE colType='string'
GROUP BY database, tableName
"""
display(spark.sql(metadata_sql_str))
For the second question, you can use the SQL builtin function regexp_extract_all() to extract indicators from columns using regular expressions. For example, the following SQL query,
SELECT regexp_extract_all('paste this https://d.test.com into the browser',
'((?!-)[A-Za-z0-9-]{1,63}(?!-)\\.)+[A-Za-z]{2,6}', 0) AS extracted
UNION ALL
SELECT regexp_extract_all('ping 1.2.3.4 then ssh to 10.0.0.1 and type',
'(\\d+\\.\\d+\\.\\d+\\.\\d+)', 0) AS extracted
will return the these results:
| extracted |
|
[“d.test.com”]
|
|
[“1.2.3.4”, “10.0.0.1”]
|
For the third question, let us consider the single table case and take the domain name system (DNS) table as an example. The DNS table contains DNS requests extracted from network packet capture files. For the DNS table, you would run the following query to perform the IOC matching against the indicators extracted from the relevant columns.
SELECT /*+ BROADCAST(ioc) */
now() AS detection_ts,
'test01.dns' AS src, aug.raw,
ioc.ioc_value AS matched_ioc,
ioc.ioc_type
FROM
(
SELECT exp.raw, extracted_obs
FROM
(
SELECT to_json(struct(d.*)) AS raw,
concat(
regexp_extract_all(d.query, '(\\d+\.\\d+\.\\d+\.\\d+)', 0),
regexp_extract_all(d.id_orig_h, '(\\d+\.\\d+\.\\d+\.\\d+)', 0),
regexp_extract_all(d.id_resp_h, '(\\d+\.\\d+\.\\d+\.\\d+)', 0),
regexp_extract_all(d.query, '((?!-)[A-Za-z0-9-]{1,63}(?!-)\\.)+[A-Za-z]{2,6}', 0)
) AS extracted_obslist
FROM test01.dns AS d
) AS exp LATERAL VIEW explode(exp.extracted_obslist) AS extracted_obs
) AS aug
INNER JOIN test01.ioc AS ioc ON aug.extracted_obs=ioc.ioc_value
Note the optional optimizer directive “BROADCAST(ioc)”. That tells the Databricks query optimizer to pick a query execution plan that broadcasts the smaller “ioc” table containing the list of IOCs to all worker nodes processing the join operator. Note also that the regular expressions provided are simplified examples (consider using the regular expressions from msticpy for production). Now, you just need to use the above query as a template and generate the corresponding SQL query for all tables with relevant columns that might contain indicators. You can view the Python code for that in the provided notebook.
Note that the amount of time needed to run those IOC matching queries would depend on the volume of data and the compute resources available to the notebook: given the same volume of data, the more compute resources, the more parallel processing, the faster the processing time.
Databricks for the threat hunting scenario
What about the threat hunting scenario? In threat hunting, your security team would typically maintain a curated list of IOCs and perform periodic IOC matching against that list of IOCs.
A few words about maintaining a curated list of IOCs. Depending on the maturity of your organization’s cybersecurity practice, the curated list of IOCs may simply be a collection of malicious IP addresses, FQDNs, hashes etc. obtained from your organization’s threat intelligence subscription that is curated by the threat hunters for relevance to your organization or industry. In some organizations, threat hunters may play a more active role in finding IOCs for inclusion, testing the prevalence statistics of the IOCs to ensure the false positive rates are manageable, and expiring the IOCs when they are no longer relevant.
When performing IOC matching using the curated list of IOCs, you may choose to skip the schema discovery steps if the databases, tables and columns are well-known and slow changing. For efficiency, you also do not want to run the IOC matching operation from scratch each time, because most of the data would have been checked during the previous run. Databricks Delta Live Tables (DLT) provide a very convenient way of turning the IOC matching query into a pipeline that runs incrementally only on the updates to the underlying tables.
CREATE STREAMING LIVE TABLE iochits
AS
SELECT now() AS detection_ts, 'test01.dns' AS src, aug.raw, ioc.ioc_value AS matched_ioc, ioc.ioc_type
FROM (
SELECT exp.raw, extracted_obs
FROM (
SELECT to_json(struct(d.*)) AS raw,
concat(
regexp_extract_all(d.query, '(\\d+\\.\\d+\\.\\d+\\.\\d+)', 0),
regexp_extract_all(d.id_orig_h, '(\\d+\\.\\d+\\.\\d+\\.\\d+)', 0),
regexp_extract_all(d.id_resp_h, '(\\d+\\.\\d+\\.\\d+\\.\\d+)', 0),
regexp_extract_all(d.query, '((?!-)[A-Za-z0-9-]{1,63}(?!-)\\.)+[A-Za-z]{2,6}', 0)) AS extracted_obslist
FROM stream(test01.dns) AS d
) AS exp LATERAL VIEW explode(exp.extracted_obslist) AS extracted_obs
) AS aug INNER JOIN test01.ioc AS ioc ON aug.extracted_obs=ioc.ioc_value
UNION ALL
SELECT now() AS detection_ts,
'test01.http' AS src,
aug.raw,
ioc.ioc_value AS matched_ioc,
ioc.ioc_type
FROM (
SELECT exp.raw, extracted_obs
FROM (
SELECT to_json(struct(d.*)) AS raw,
concat(
regexp_extract_all(d.origin, '(\\d+\\.\\d+\\.\\d+\\.\\d+)', 0),
regexp_extract_all(d.referrer, '(\\d+\\.\\d+\\.\\d+\\.\\d+)', 0),
regexp_extract_all(d.id_orig_h, '(\\d+\\.\\d+\\.\\d+\\.\\d+)', 0),
regexp_extract_all(d.host, '(\\d+\\.\\d+\\.\\d+\\.\\d+)', 0),
regexp_extract_all(d.id_resp_h, '(\\d+\\.\\d+\\.\\d+\\.\\d+)', 0),
regexp_extract_all(d.referrer, '((?!-)[A-Za-z0-9-]{1,63}(?!-)\\.)+[A-Za-z]{2,6}', 0)) AS extracted_obslist
FROM stream(test01.http) AS d
) AS exp LATERAL VIEW explode(exp.extracted_obslist) AS extracted_obs
) AS aug INNER JOIN test01.ioc AS ioc ON aug.extracted_obs=ioc.ioc_value;
In fact, you have full control over the degree of incremental processing: you can execute the incremental processing continuously or at scheduled intervals.
When you start executing a hunting query periodically or continuously, is that not in the realm of detection rather than hunting? Indeed it is a fine line to tread. Hunting queries tend to be fewer and lower in fidelity while detection rules are in the thousands and high false positive rates are simply not acceptable. The resulting processing characteristics are also different. The problem of scaling detection processing to thousands of detection rules on large volumes of log and telemetry data is actually quite amenable to parallelization since the detection rules are almost always independent. Both streaming and micro-batching approaches can be used to incrementally perform detection processing as new log and telemetry data arrives. Hunt queries tend to be few, but each query tries to cover a lot more data and hence requires more resources to process.
What about hunts and investigations that are more ad hoc in nature? Is there any way to make those queries work at interactive speeds? This is a common request from threat hunters especially for voluminous network log data such DNS data.
An elegant and effective way to do this is to maintain a highly-aggregated summary structure as a materialized view. For example, for DNS data, the summary structure will only hold DNS records aggregated using buckets for each unique value of (date, sourceTable, indicator_value, sourceIP, destinationIP). Threat hunters would first query this summary structure and then use the fields in the summary record to query the source table for details. The Databricks DLT feature again provides a convenient way to create pipelines for maintaining those summary structures and the following shows the SQL for the DNS summary table.
CREATE STREAMING LIVE TABLE ioc_summary_dns
AS
SELECT ts_day, obs_value, src_data, src_ip, dst_ip, count(*) AS cnt
FROM
(
SELECT 'test01.dns' AS src_data,
extracted_obs AS obs_value,
date_trunc('DAY',
timestamp(exp.ts)) as ts_day,
exp.id_orig_h as src_ip,
exp.id_resp_h as dst_ip
FROM
(
SELECT d.*,
concat(
regexp_extract_all(d.query, '(\\d+\\.\\d+\\.\\d+\\.\\d+)', 0),
ARRAY(d.id_orig_h),
ARRAY(d.id_resp_h),
regexp_extract_all(d.query, '((?!-)[A-Za-z0-9-]{1,63}(?!-)\\.)+[A-Za-z]{2,6}', 0)
) AS extracted_obslist
FROM stream(test01.dns) AS d
) AS exp LATERAL VIEW explode(exp.extracted_obslist) AS extracted_obs
) AS aug
GROUP BY ts_day, obs_value, src_data, src_ip, dst_ip;
You would create separate DLT pipelines for each source table and then create a view to union all the summary tables into one single view for querying as illustrated by the following SQL.
CREATE VIEW test01.ioc_summary_all
AS
SELECT * FROM test01.ioc_summary_dns
UNION ALL
SELECT * FROM test01.ioc_summary_http
How do the summary tables help?
Considering the DNS table, recall that the summary structure will only hold DNS records aggregated for each unique value of (date, sourceTable, indicator_value, sourceIP, destinationIP). Between the same source-destination IP pair, there may be thousands of DNS requests for the same FQDN in a day. In the aggregated summary table, there is just one record to represent the potentially hundreds to thousands of DNS requests for the same FQDN between the same source-destination address pair. Hence summary tables are a lossy compression of the original tables with a compression ratio of at least 10x. Querying the much smaller summary tables is therefore much more performant and interactive. Moreover the compressed nature of the summary structure means it can cover a much longer retention period compared to the original data. You do lose time resolution with the aggregation, but at least it gives you the much needed visibility during an investigation. Just think about how the summary structure would be able to tell you whether you were affected by the Sunburst threat even when the threat was discovered nine months after the first suspicious activity.
Conclusion
In this blog post, we have given you a glimpse of the lakehouse for cybersecurity that is open, low-cost and multi-cloud. Zooming in on the fundamental operation of IOC matching, we have given you a taste of how the Databricks Lakehouse platform enables it to be performed with ease and simplicity across all security relevant data ingested from your attack surface.
We invite you to
--
Try Databricks for free. Get started today.
The post Hunting for IOCs Without Knowing Table Names or Field Labels appeared first on Databricks.























 Search in the sidebar. The Search dialog appears.
Search in the sidebar. The Search dialog appears.