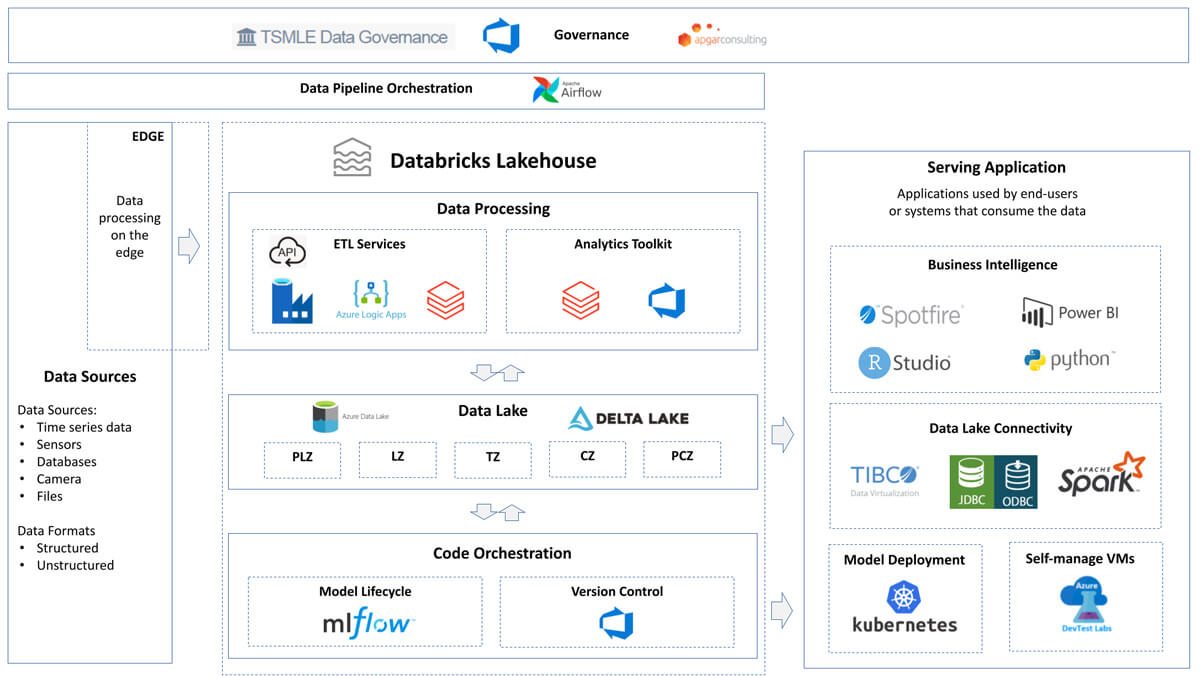
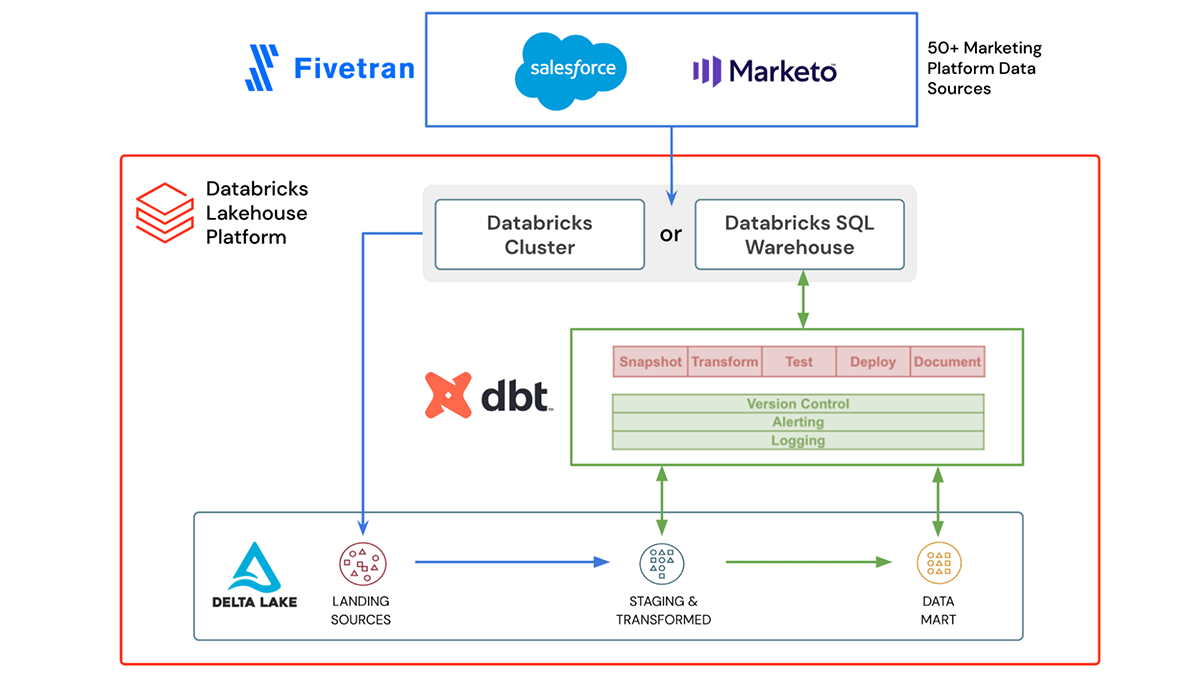
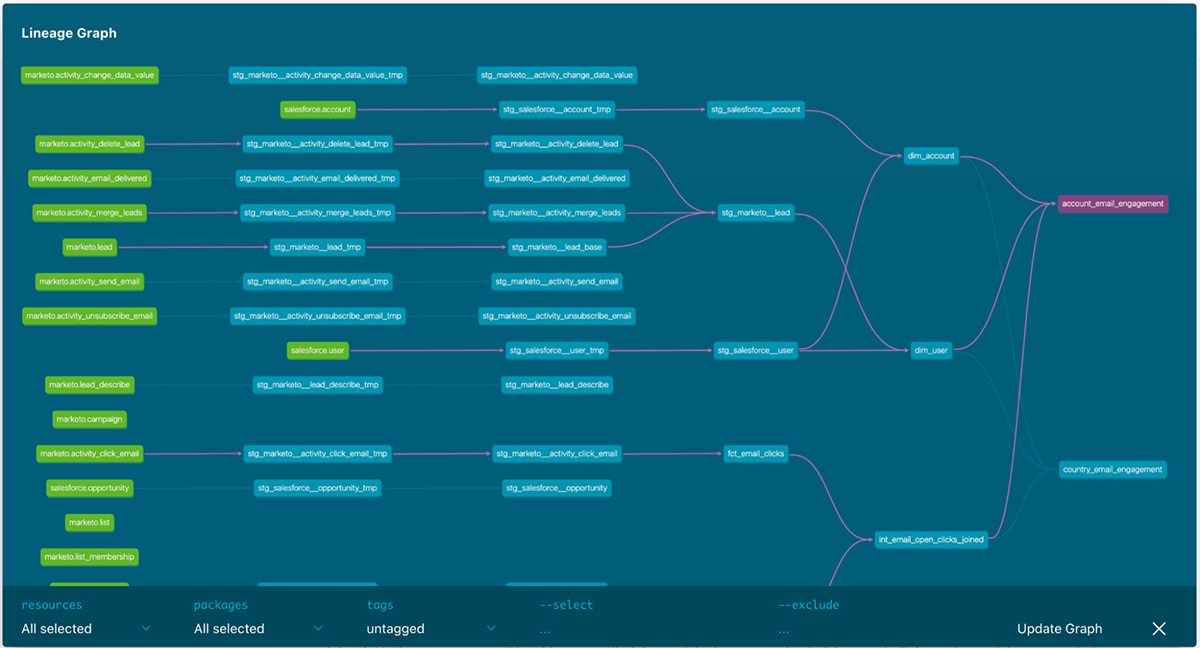
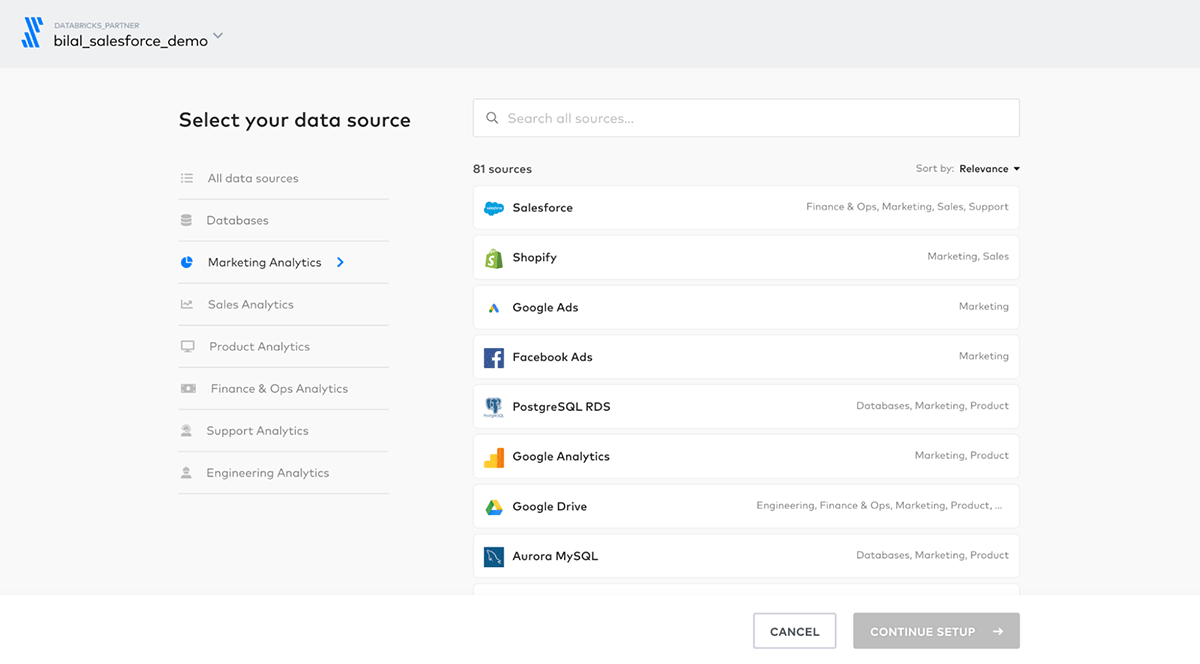
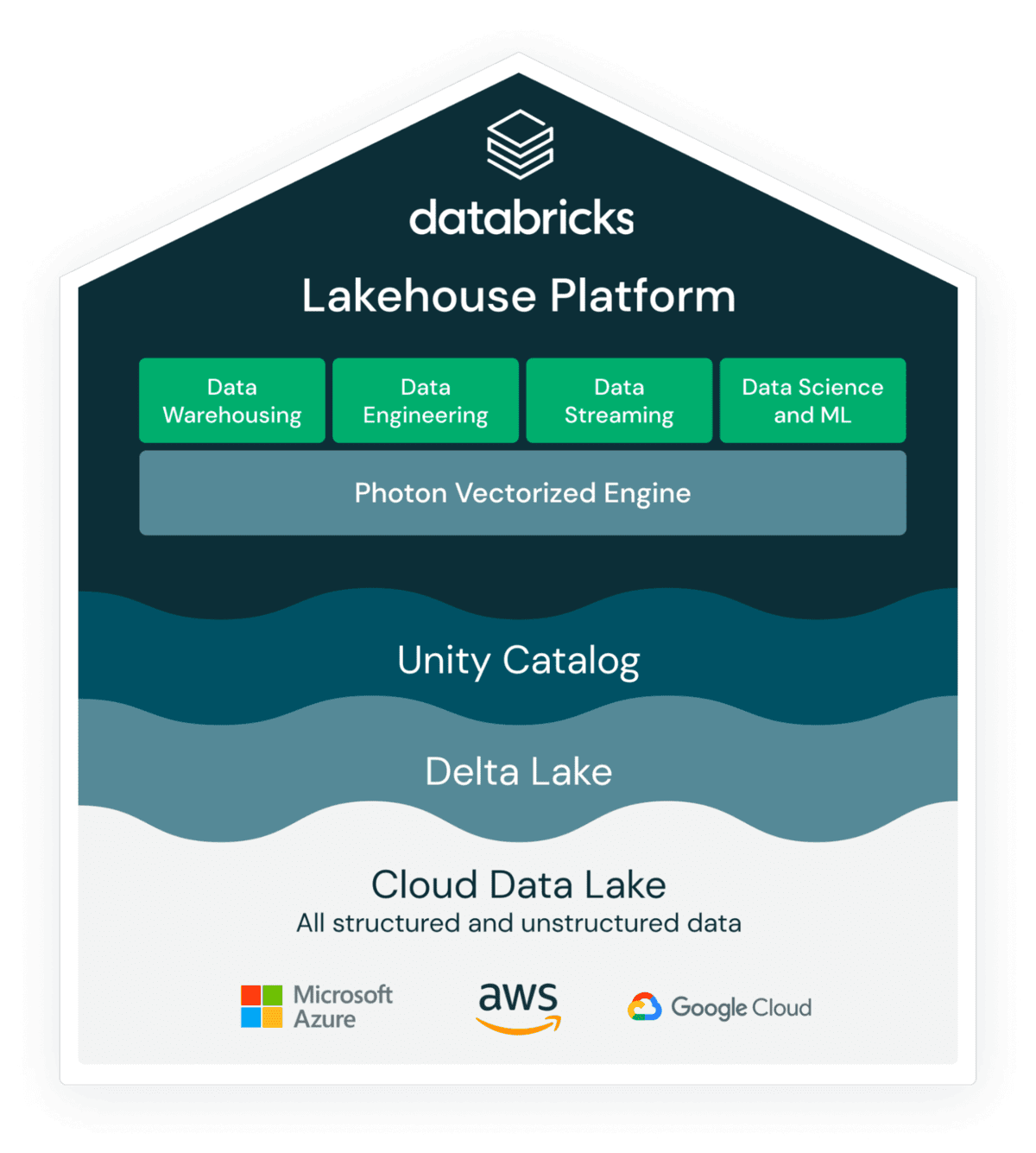
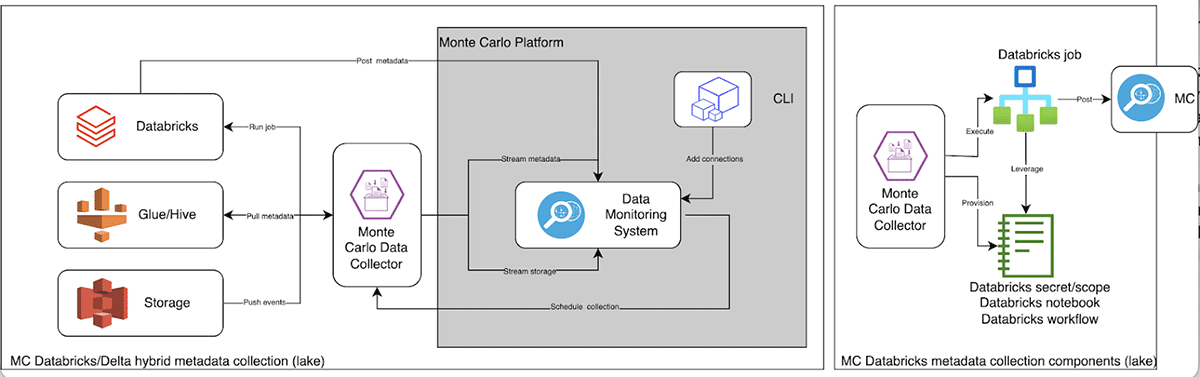
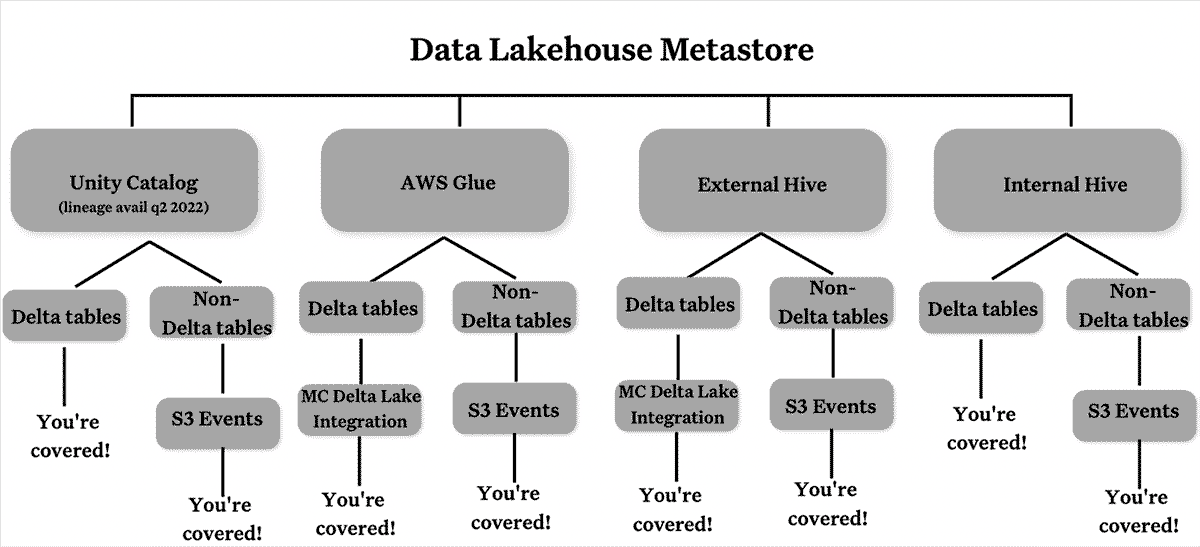
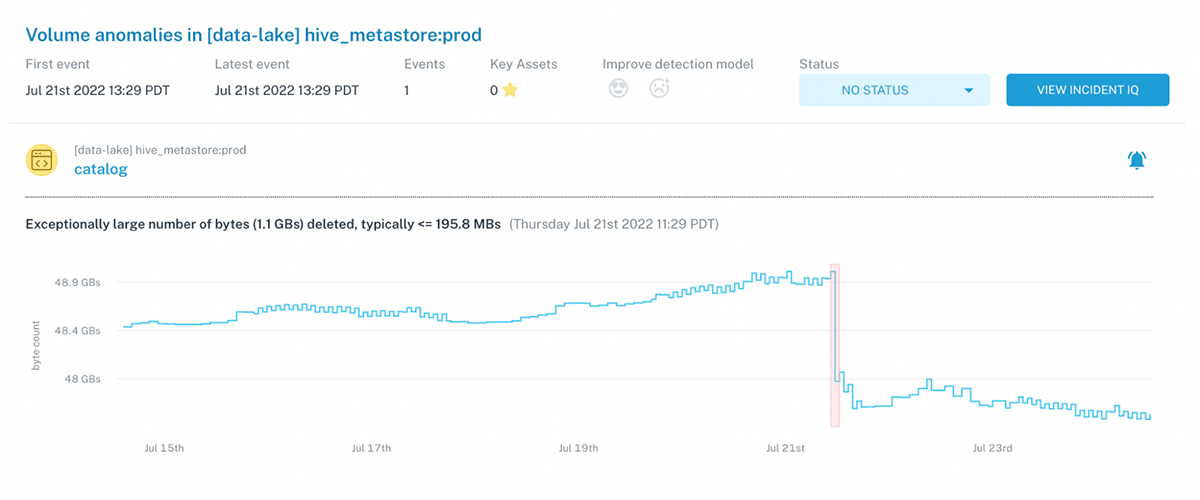
Data teams have never been more important to the world. Over the past few years we’ve seen many of our customers building a new generation of data and AI applications that are reshaping and transforming every industry with the lakehouse.
The data lakehouse paradigm introduced by Databricks is the future for modern data teams seeking to build solutions that unify analytics, data engineering, machine learning, and streaming workloads across clouds on one simple, open data platform.
Many of our customers, from enterprises to startups across the globe, love and trust Databricks. In fact, half of the Fortune 500 are seeing the lakehouse drive impact. Organizations like John Deere, Amgen, AT&T, Northwestern Mutual and Walgreens, are making the move to the lakehouse because of its ability to deliver analytics and machine learning on both structured and unstructured data.
Last month we unveiled innovation across the Databricks Lakehouse Platform to a sold-out crowd at the annual Data + AI Summit. Throughout the conference, we announced several contributions to popular data and AI open source projects as well as new capabilities across workloads.
Open sourcing all of Delta Lake
Delta Lake is the fastest and most advanced multi-engine storage format. We’ve seen incredible success and adoption thanks to the reliability and fastest performance it provides. Today, Delta Lake is the most widely used storage layer in the world, with over 7 million monthly downloads; growing by 10x in monthly downloads in just one year.
We announced that Databricks will contribute all features and enhancements it has made to Delta Lake to the Linux Foundation and open source all Delta Lake APIs as part of the Delta Lake 2.0 release.
Delta Lake 2.0 will bring unmatched query performance to all Delta Lake users and enable everyone to build a highly performant data lakehouse on open standards. With this contribution, Databricks customers and the open source community will benefit from the full functionality and enhanced performance of Delta Lake 2.0. The Delta Lake 2.0 Release Candidate is now available and is expected to be fully released later this year. The breadth of the Delta Lake ecosystem makes it flexible and powerful in a wide range of use cases.
Spark from Any Device and Next Generation Streaming Engine
As the leading unified engine for large-scale data analytics, Spark scales seamlessly to handle data sets of all sizes. However, the lack of remote connectivity and the burden of applications developed and run on the driver node, hinder the requirements of modern data applications. To tackle this, Databricks introduced Spark Connect, a client and server interface for Apache Spark™ based on the DataFrame API that will decouple the client and server for better stability, and allow for built-in remote connectivity. With Spark Connect, users can access Spark from any device.
Data streaming on the lakehouse is one of the fastest-growing workloads within the Databricks Lakehouse Platform and is the future of all data processing. In collaboration with the Spark community, Databricks also announced Project Lightspeed, the next generation of Spark Structured Streaming engine for data streaming on the lakehouse.
Expanding Data Governance, Security, and Compliance Capabilities
For organizations, governance, security, and compliance are critical because they help guarantee that all data assets are maintained and managed securely across the enterprise and that the company is in compliance with regulatory frameworks. Databricks announced several new capabilities that further expand data governance, security, and compliance capabilities.
- Unity Catalog will be generally available on AWS and Azure in the coming weeks, Unity Catalog offers a centralized governance solution for all data and AI assets, with built-in search and discovery, automated lineage for all workloads, with performance and scalability for a lakehouse on any cloud.
- Databricks also introduced Data lineage, for Unity Catalog earlier last month, significantly expanding data governance capabilities on the lakehouse and giving data teams a complete view of the entire data lifecycle. With data lineage, customers gain visibility into where data in their lakehouse came from, who created it and when, how it has been modified over time, how it’s used across data warehousing and data science workloads, and much more.
- Databricks extended capabilities for customers in highly regulated industries to help them maintain compliance with Payment Card Industry Data Security Standard (PCI-DSS) and Health Insurance Portability and Accountability Act (HIPAA). Databricks extended HIPAA and PCI-DSS compliance features on AWS for multi-tenant E2 architecture deployments, and now also provides HIPAA Compliance features on Google Cloud (both are in public preview).
Safe, open sharing allows data to achieve new value without vendor lock-in
Data sharing has become important in the digital economy as enterprises wish to easily and securely exchange data with their customers, partners, suppliers and internal line of business to better collaborate and unlock value from that data. To address the limitations of existing data sharing solutions, Databricks developed Delta Sharing, with various contributions from the OSS community, and donated it to the Linux Foundation. We announced Delta Sharing will be generally available in the coming weeks.
Databricks is helping customers share and collaborate with data across organizational boundaries and we also unveiled enhancements to data sharing enabled by Databricks Marketplace and Data Cleanrooms.
- Databricks Marketplace: Available in the coming months, Databricks Marketplace provides an open marketplace to package and distribute data sets and a host of associated analytics assets like notebooks, sample code and dashboards without vendor lock-in.
- Data Cleanrooms: Available in the coming months, Data Cleanrooms for the lakehouse will provide a way for companies to safely discover insights together by partnering in analysis without having to share their underlying data.
The Best Data Warehouse is a Lakehouse
Data warehousing is one of the most business-critical workloads for data teams. Databricks SQL (DBSQL) is a serverless data warehouse on the Databricks Lakehouse Platform that lets you run all your SQL and BI applications at scale with up to 12x better price/performance, a unified governance model, open formats and APIs, and your tools of choice – no lock-in. Databricks unveiled new data warehousing capabilities in its platform to enhance analytics workloads further:
- Databricks SQL Serverless is now available in preview on AWS, providing instant, secure and fully managed elastic compute for improved performance at a lower cost.
- Photon, the record-setting query engine for lakehouse systems, will be generally available on Databricks Workspaces in the coming weeks, further expanding Photon’s reach across the platform. In the two years since Photon was announced, it has processed exabytes of data, run billions of queries, delivered benchmark-setting price/performance at up to 12x better than traditional cloud data warehouses.
- Open source connectors for Go, Node.js, and Python make it even simpler to access the lakehouse from operational applications, while the Databricks SQL CLI enables developers and analysts to run queries directly from their local computers.
- Databricks SQL now provides query federation, offering the ability to query remote data sources including PostgreSQL, MySQL, AWS Redshift, and others without the need to first extract and load the data from the source systems.
- Python UDFs deliver the power of Python right into Databricks SQL! Now analysts can tap into python functions – from complex transformation logic to machine learning models – that data scientists have already developed and seamlessly use them in their SQL statements.
- Adding support for Materialized Views (MVs) to accelerate end-user queries and reduce infrastructure costs with efficient, incremental computation. Built on top of Delta Live Tables (DLT), MVs reduce query latency by pre-computing otherwise slow queries and frequently used computations.
- Primary Key & Foreign Key Constraints provides analysts with a familiar toolkit for advanced data modeling on the lakehouse. DBSQL & BI tools can then leverage this metadata for improved query planning.
Reliable Data Engineering
Tens of millions of production workloads run daily on Databricks. With the Databricks Lakehouse Platform, data engineers have access to an end-to-end data engineering solution for ingesting and transforming batch and streaming data, orchestrating reliable production workflows at scale, and increasing the productivity of data teams with built-in data quality testing and support for software development best practices.
We recently announced general availability on all three clouds of Delta Live Tables (DLT), the first ETL framework to use a simple, declarative approach to building reliable data pipelines. Since its launch earlier this year, Databricks continues to expand DLT with new capabilities. We are excited to announce we are developing Enzyme, a performance optimization purpose-built for ETL workloads. Enzyme efficiently keeps up-to-date a materialization of the results of a given query stored in a Delta table. It uses a cost model to choose between various techniques, including techniques used in traditional materialized views, delta-to-delta streaming, and manual ETL patterns commonly used by our customers. Additionally, DLT offers new enhanced autoscaling, purpose-built to intelligently scale resources with the fluctuations of streaming workloads, and CDC Slowly Changing Dimensions—Type 2, easily tracks every change in source data for both compliance and machine learning experimentation purposes .When dealing with changing data (CDC), you often need to update records to keep track of the most recent data. SCD Type 2 is a way to apply updates to a target so that the original data is preserved.
We also recently announced general availability on all three clouds of Databricks Workflows, the fully managed lakehouse orchestration service for all your teams to build reliable data, analytics and AI workflows on any cloud. Since its launch earlier this year, Databricks continues to expand Databricks Workflows with new capabilities including Git support for Workflows now available in Public Preview, running dbt projects in production, new SQL task type in Jobs, new “Repair and Rerun” capability in Jobs, and context sharing between tasks.
Production Machine Learning at Scale
Databricks Machine Learning on the lakehouse provides end-to-end machine learning capabilities from data ingestion and training to deployment and monitoring, all in one unified experience, creating a consistent view across the ML lifecycle and enabling stronger team collaboration. We continue to innovation across the ML lifecycle to enable you to put models faster into production –
- MLflow 2.0, As one of the most successful open source machine learning (ML) projects, MLflow has set the standard for ML platforms. The release of MLflow 2.0 introduces MLflow Pipelines to make MLOps simple and get more projects to production. It offers out of box templates and provides a structured framework that enables to teams to automate the handoff from experimentation to production. You can preview this functionality with the latest version of MLflow.
- Serverless Model Endpoints, Deploy your models on Serverless Model Endpoints for real-time inference for your production application, without the need to maintain your own infrastructure. Users can customize autoscaling to handle their model’s throughput and for predictable traffic use cases, and teams can save costs by autoscaling all the way down to zero.
- Model Monitoring, Track the performance of your production models with Model Monitoring. It auto-generates dashboards to help teams view and analyze data and model quality drift. Model Monitoring also provides the underlying analysis and drift tables as Delta tables so teams can join performance metrics with business value metrics to calculate business impact as well as create alerts when metrics have fallen below specified thresholds.
Learn more
Modern data teams need innovative data architectures to meet the requirements of the next generation of Data and AI applications. The lakehouse paradigm provides a simple, multicloud, and open platform and it remains our mission to continue supporting all our customers who want to be able to do business intelligence, AI, and machine learning in one platform. You can watch all our Data and AI Summit keynotes and breakout sessions on demand to learn more about these announcements. You can also download the Data Team’s Guide to the Databricks Lakehouse Platform for a deeper dive to the Databricks Lakehouse Platform.
--
Try Databricks for free. Get started today.
The post Recap of Databricks Lakehouse Platform Announcements at Data and AI Summit 2022 appeared first on Databricks.