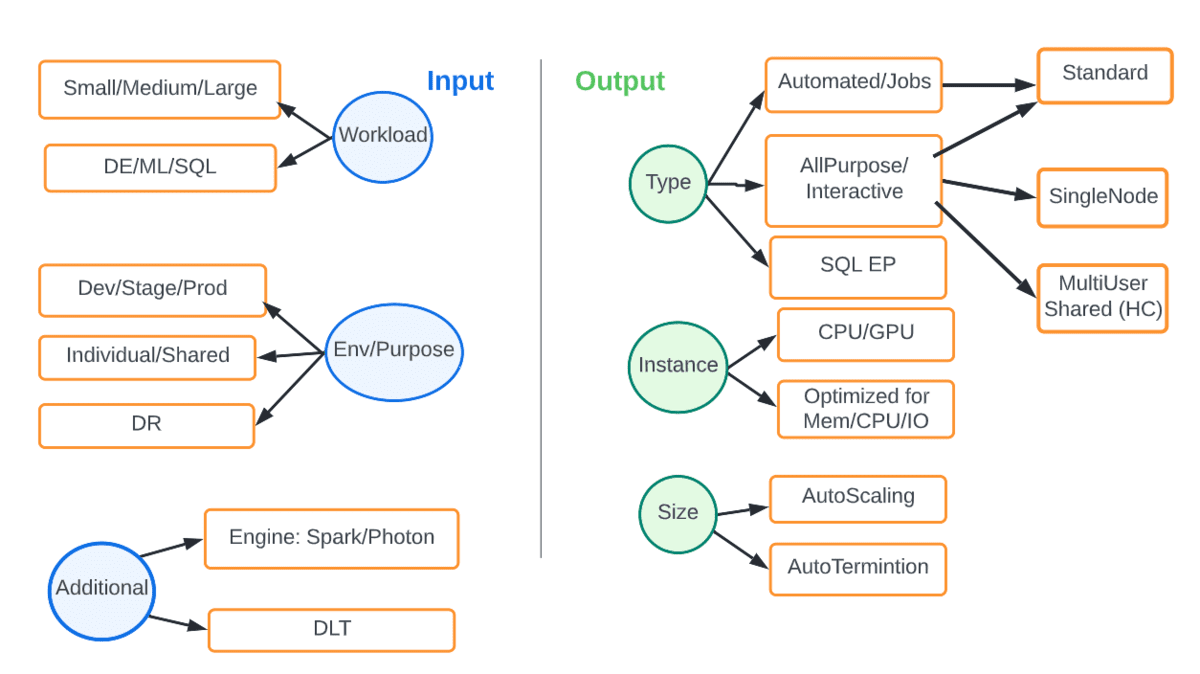
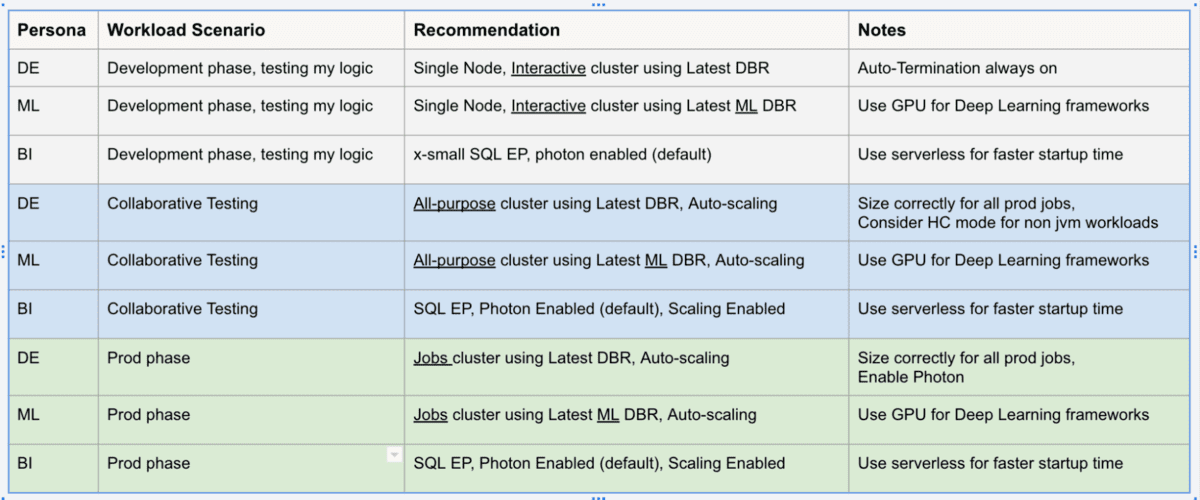
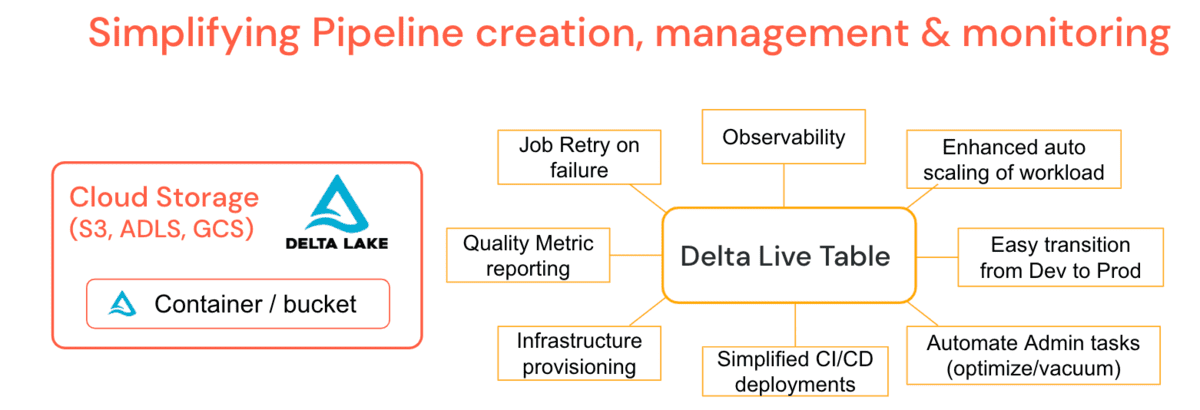
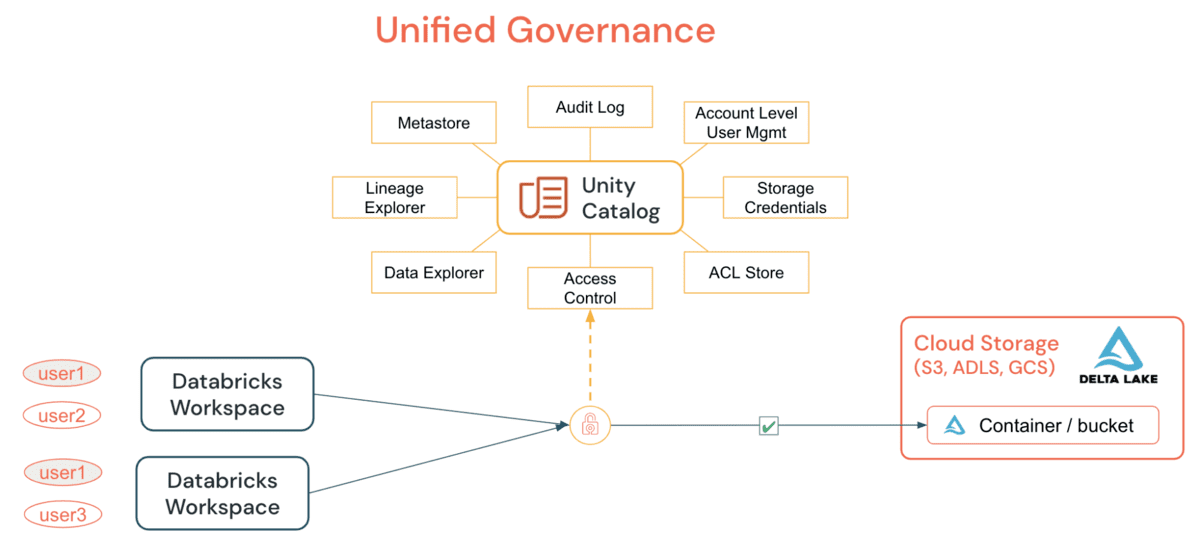
Manufacturing is an evolutionary business, grounded upon infrastructure, business processes, and manufacturing operations built over decades in a continuum of successes, insights and learnings. The methods and processes used to approach the development, launch, optimization of products and capital spend are the foundation of the industry’s evolution.
Today’s data and AI-driven businesses are rewarded by leveraging process and product optimization use cases not previously possible, are able to forecast and sense supply chain demand, and, crucially, introduce new forms of revenue based upon service rather than product.
The drivers for this evolution? The emergence of what we refer to as “Intelligent Manufacturing” is enabled by the rise of computational power at the Edge, in the Cloud, new levels of connectivity speed enabled by 5G and fiber optic, and combined with increased use of advanced analytics and machine learning (ML).
Yet even with all the technological advances enabling these new data-driven business, challenges exist. McKinsey’s recent research with the World Economic Forum
estimates the value creation potential of manufacturers and suppliers that implement Industry 4.0 in their operations at USD$37 trillion by 2025. Truly a huge number. But the challenge that most companies still struggle with is the move from piloting point solutions to delivering sustainable impact at scale. Only 30% of companies are capturing value from Industry 4.0 solutions in manufacturing today.
Over the last two years demand imbalances and supply chain swings have added a sense of urgency for manufacturers to digitally transform. But in truth the main challenges facing the industry have existed, and will continue to exist, outside these recent exceptional circumstances. Manufacturers will always strive for greater levels of visibility across their supply chain, always seek to optimize and streamline operations to improve margins. In a recent Omdia/Databricks survey, manufacturers confirmed their continuing quest to improve efficiency, productivity, adaptability, and resilience seeking to deliver increased profitability, increased productivity (throughput) and create new revenue streams.

Current Manufacturing Business Objectives
Keenly conscious that financial value must be delivered to both the CDAO, CIO and Line of Business owners when approaching technology driven data transformation solutions, the following product innovations announced at the recent Data + AI Summit are organized so that each can easily be related to the manufacturing value stream.
Operations Optimization and Creating Agile Supply Chains
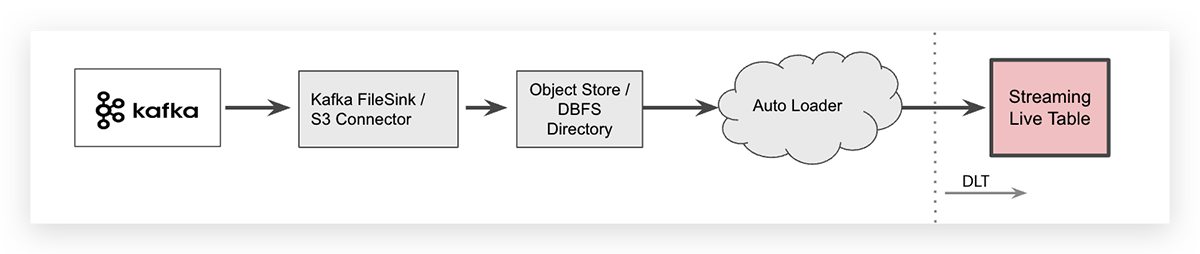
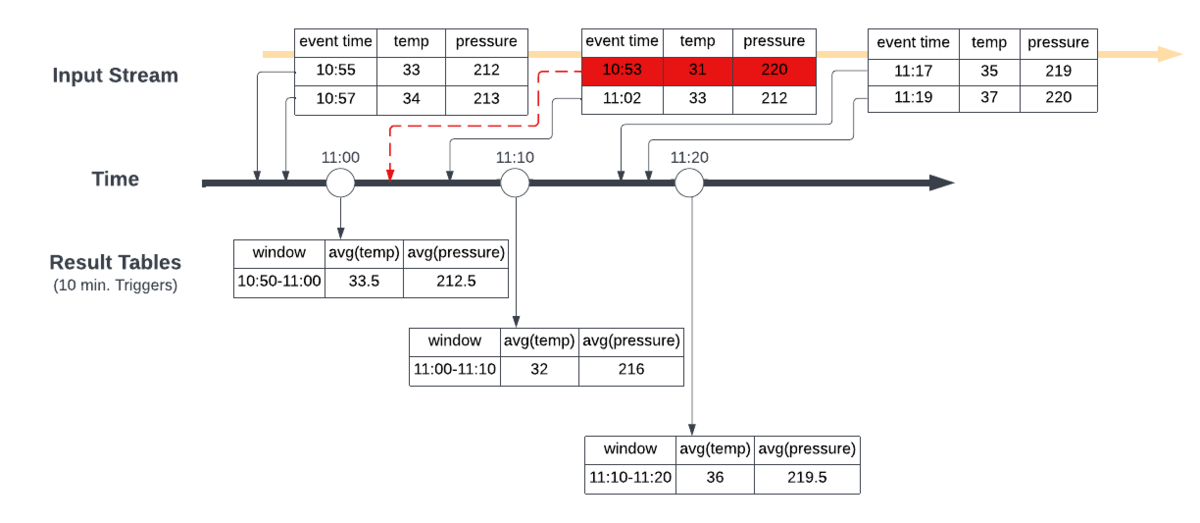
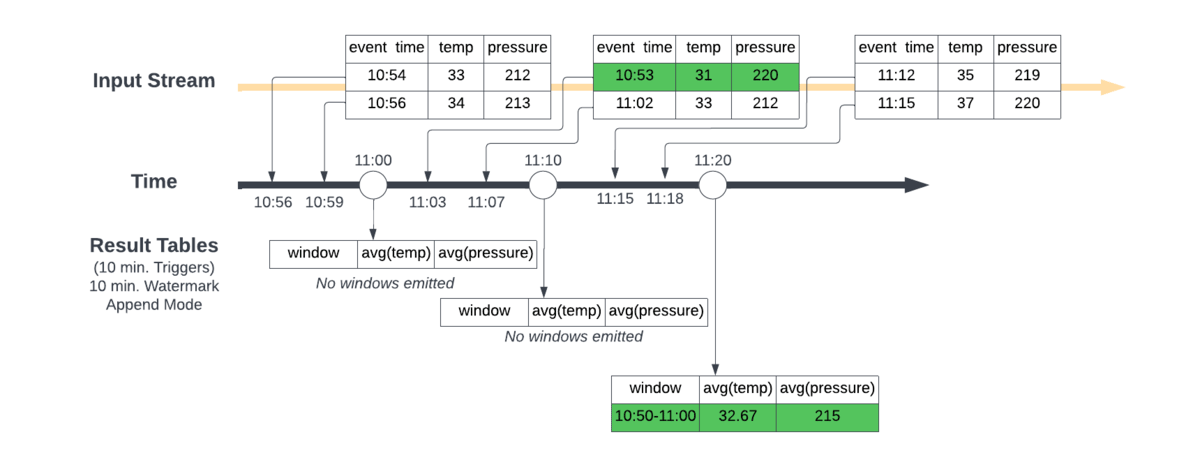
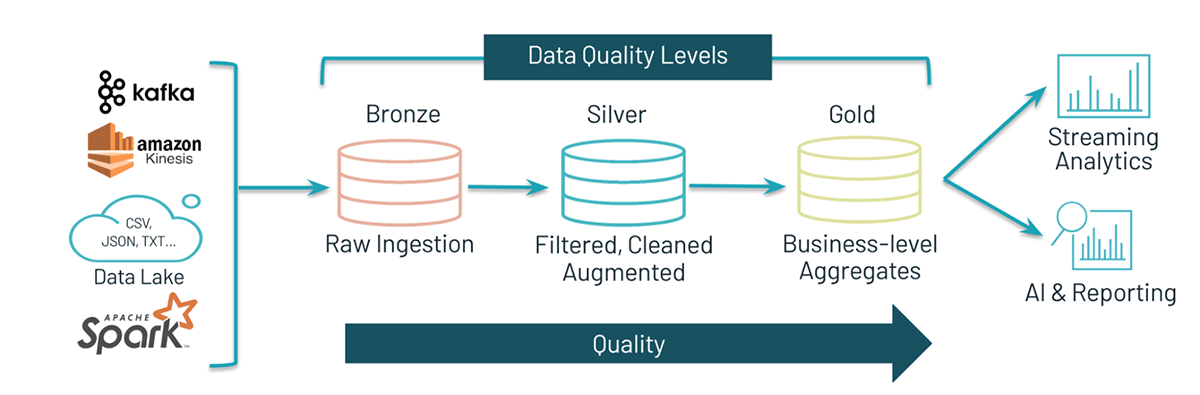
Streaming data combined with IT/OT data convergence power today’s Connected Manufacturers by enabling value producing use cases like real-time advanced process control and optimization, supply chain demand forecasting and computer vision enabled quality assurance. The key to unlocking these use cases is the ability to stream data sources and process it in near real time. At the Data + AI Summit, Databricks announced Project Light Speed whose objective is to improve performance achieving higher throughput, lower latency and lower cost. The announcement includes improving ecosystem support for connectors, enhancing functionality for processing data with new operators and APIs, simplifying deployment, operations, monitoring and troubleshooting.
Streaming data is important to companies like Cummins, a multinational corporation that designs, manufactures, and distributes engines, filtration, and power generation products, using streaming to collect telemetry data from engines and analyze it in real-time for maintenance alerts.
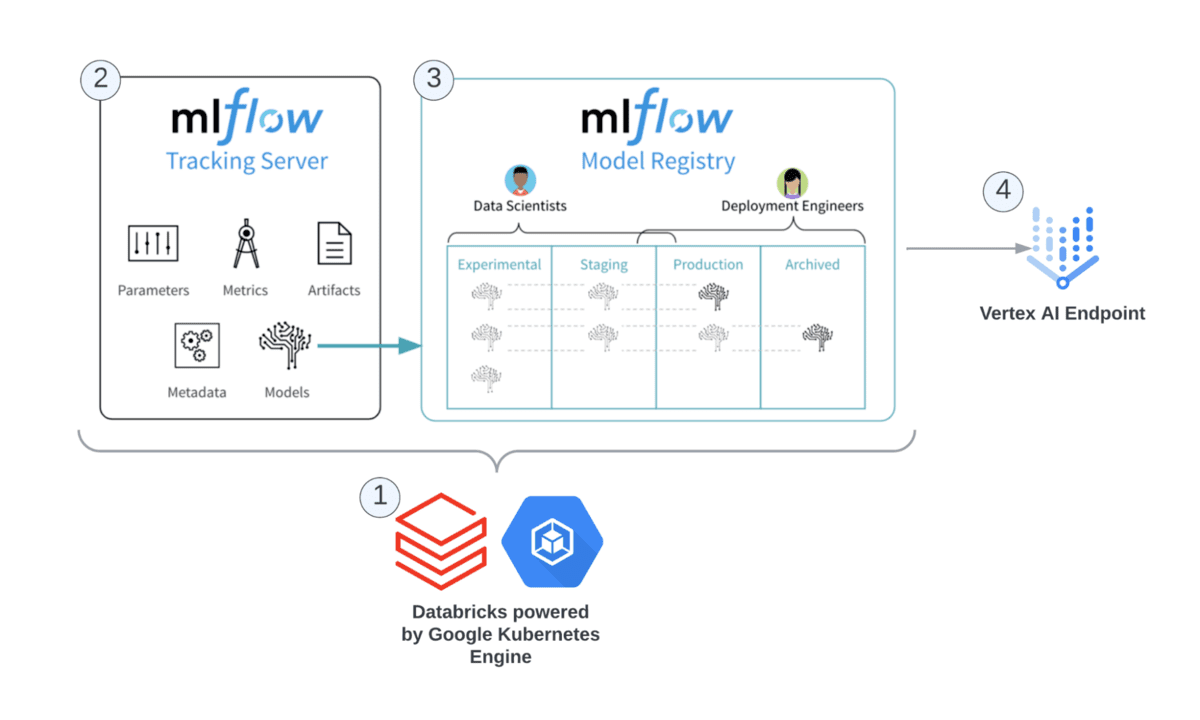
If streaming data is a foundational core of Connected Manufacturing, advanced analytics built on machine learning and AI is the true pinnacle of value. The challenge that both CIOs and Line of Business Owners have is that if the creation, testing and deployment of these models is not easy, scalable and trusted they will not be used by data scientists or more importantly, the business they serve.
Innovations in MLflow Pipelines was announced that enable Data Scientists to create production-grade ML pipelines that combine modular ML code with software engineering best practices to make model development and deployment fast and scalable. The new features around model monitoring will be impactful for manufacturing as it’s common for our customers and prospects to have a significant number of models that span operations, supply chains and sales/marketing. It becomes impossible to do proper model drift monitoring without some automated framework. MLflow Pipelines will help improve model governance frameworks because manufacturers can now apply CI/CD practices around constructing and managing ML model infrastructure setup. This service makes Databricks ML robust for production workloads as customers can monitor their model, diagnose fluctuations in performance and address the underlying issues.
More information on MLflow Pipelines – Blog
Serverless Model Endpoints improve upon existing Databricks-hosted model serving by offering horizontal scaling to thousands of queries per second (QPS) , potential cost savings through auto-scaling, and operational metrics for monitoring runtime performance. Ultimately, this means Databricks-hosted models are suitable for production use at scale. Across many of our manufacturing customers, a significant number of models are being deployed and companies struggled, until now, with the cost aspect of having to spin up a single cluster for every endpoint. Serverless endpoints allow manufacturers to :
- Keep model deployments within the Databricks ecosystem
- Reduce time required to deploy ML models to production
- Reduce overall architectural complexity – no need to use native services from cloud vendors
- Accelerate the journey to unified MLOps and model governance across the organization – an important outcome from the perspective of increasing regulatory oversight and scrutiny
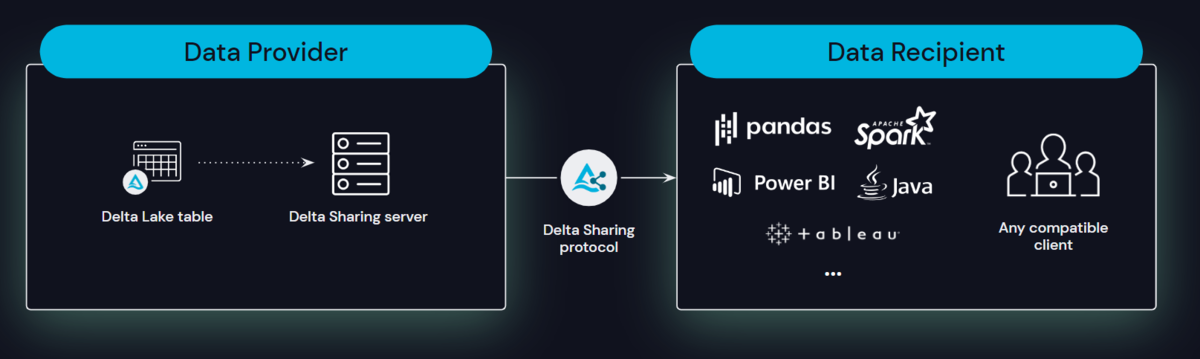
Supply chains benefit from innovations in intra and inter company data sharing with the introduction of data clean rooms within Unity Catalog. Data cleanrooms open a broad array of use cases across within manufacturing supply chain and tolling operations allowing for collaboration across the value chain establishing predictive demand forecasting or providing tollers with anonymized process optimization data
With Unity Catalog, you can enable fine-grained access controls on the data and meet your privacy requirements. Integrated governance allows participants to have full control over queries or jobs that can be executed on their data.
Manufacturing supply chains gain the ability to see three levels deep within a supply chain, without compromising intellectual property when dealing with multiple suppliers/vendors in the supply chain.
Cleanrooms also open new business models by paving the way for building networks of collaboration between Manufacturers and other adjacent industries (e.g. Consumer Goods, and Retailers as examples) to build seamless customer experiences across multiple facets of everyday life.
More information on Unity Catalog – Blog
More information on Serverless Model Endpoints (Available late Q2, early Q3 in Gated Public Preview) – Blog
More information Delta Sharing – Data Cleanrooms – Blog

Databricks Marketplace
Organizational Considerations
In the present time of the Great Resignation and now pressures of a potential business slowdown, organizational stability is on all executives minds. Databricks sees the power of open source solutions and announced that Delta Lake 2.0 will be completely open source.
What does this mean for your business?
- You’ll have a larger pool of skilled recruits to pull from that have broad technical knowledge instead of being beholden to technical expertise in black box solutions
- Your data teams will come up to speed quick leveraging a common platform
- Leveraging Unity Catalog your data will be accessible to a wider audience while still maintaining governance
- Lower SQL costs with Databricks SQL Serverless means more people will use and your business will democratize data within all groups allowing for for more granular insights driving your business
- As an additional organizational benefit, It is important to note that in a recent analysis of our customers market performance, our top Databricks manufacturing Lakehouse customers outperformed the overall market by over 200% over the last two years.
Shell Oil is a representative example of Lakehouse enabled value produced as it had large volumes of disjointed data and legacy architectures making scalable ML difficult over 70+ use cases. The Lakehouse architecture on Delta Lake is unifying data warehousing, BI, and ML enabling new use cases not possible before such as IoT (machinery, smart meters, etc), streaming video, internal reporting (HR/Finance), ETL for exploring SQL analytics and reporting for internal decision making.
More information on Delta Lake – Blog

Faster SQL Queries
Generation of New Revenue Streams
As indicated earlier in the Omdia/Databricks survey, generation of new revenue streams is the third most important business initiatives. Databricks is responding to this need by introducing Databrick Marketplace built on Delta Sharing, an open marketplace for exchanging data products such as datasets, notebooks, dashboards, and machine learning models. To accelerate insights, data consumers can discover, evaluate, and access more data products from third-party vendors than ever before.

Databricks Marketplace
Manufacturers can accelerate projects to monetise data and build alternative streams of revenue (e.g. selling anonymized process data or product component data to be used in predictive maintenance insights). The Databricks Marketplace will set the stage for manufacturers to finally start treating data as an asset on the balance sheet.
More information on Databricks Marketplace – Blog
For more information Databricks and these exciting product announcements click here and included are several manufacturing centric Breakout Sessions from the Data + AI Summit you might be interested in:
Breakout Sessions
Why a Data Lakehouse is Critical During the Manufacturing Apocalypse – Corning
Predicting and Preventing Machine Downtime with AI and Expert Alerts – John Deere
How to Implement a Semantic Layer for Your Lakehouse – AtScale
Applied Predictive Maintenance in Aviation: Without Sensor Data – FedEx Express
Smart Manufacturing: Real-time Process Optimization with Databricks – Tredence
The Manufacturing Industry Forum
--
Try Databricks for free. Get started today.
The post Delivering Product Innovation to Maximize Manufacturing’s Return on Capital appeared first on Databricks.